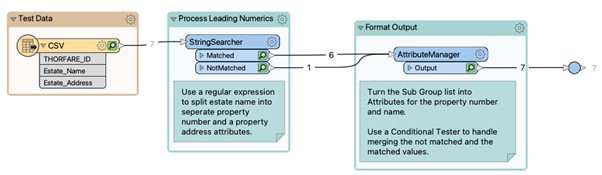
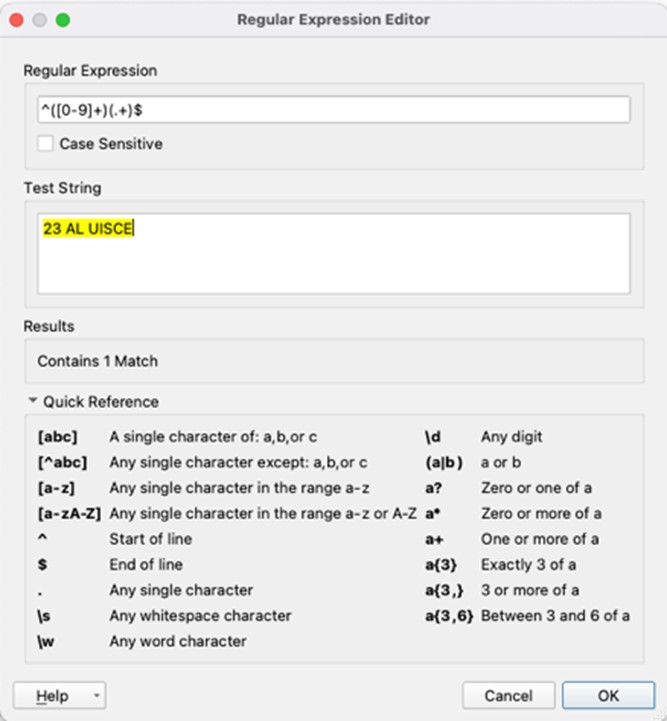
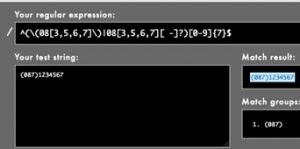
This might as well have been hieroglyphics but when you break down the expression it actually quite simple. This expression states that the string must begin with at least one or more digits with each digit being from 0-9. So this can be 1, 26, 45, 111. The ^([0-9]+) is the part of the expression that tells us this. ^ means at the start or begin with. This is followed by a set of parentheses ( ). The parentheses indicate a capturing group. This is group 1. The next set of parentheses would be group 2 and so on. Don’t worry if capturing groups do not make sense at this stage, when we return to FME to talk through and run an expression it will be a lot clearer. Inside the first group we have [0-9]+, the [0-9] is a character set of 0, 1, 2, 3, 4, 5, 6, 7, 8 ,9 and the + means one or more. So if we take ^([0-9]+) you can see that this means, match strings that begin with one or more numerical digits. If the + was not present, this would mean that the string could only begin with one digit from the character set.
The next capturing group (.+) had us scratching our heads at first because it just contains symbols. The dot or period simply means match any character, like a wildcard. We have already met the + symbol. This group says match at least one character to any amount of characters. Again, if we removed the + it would only match one (any) character. The $ means the end of the string. So, match one or more characters until the end of the string.
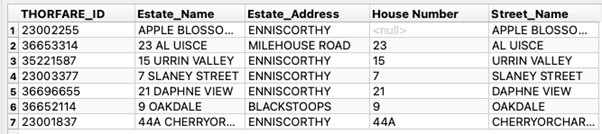
Let’s look at that expression again in its entirety. The string must begin with at least one digit or more followed by at least one or more characters until the end of the string. We will use 9 OAKDALE as an example. This begins with a single digit so the initial criteria ^([0-9]+) is met. 9 belongs to group 1. This is followed by a space, which is also a character, and followed by seven more characters until the end of the string. This satisfies the (.+)$ and places OAKDALE(with the space in front of it) into group 2.
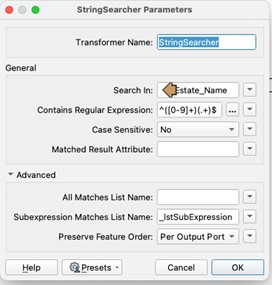
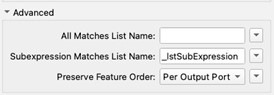
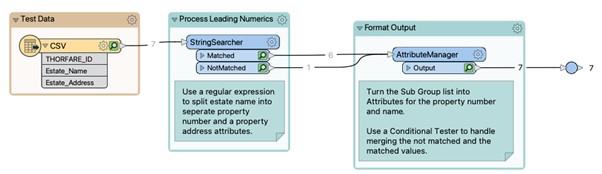
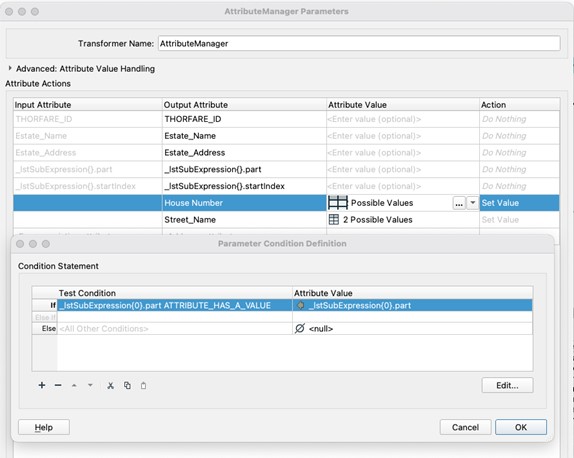
In the FME workflow in Fig 1, both groups will be output as the matched result recreating what we had initially! As we are using groups, we need to create a subexpression List under the transformers Advanced settings. This will output a List with two elements, one for each of our subgroups, this includes both the found string but also its starting position within the original string value.