Regular Expressions or understanding search Hieroglyphs!




Regular expressions are a sequence of characters that specifies a search pattern. Usually, such patterns are used by string-searching algorithms for “find” or “find and replace” operations on strings, or for input validation. They are therefore incredibly powerful when it comes to validating data, ensuring data matches an expected structure or as we will see below in aiding tasks such as address cleaning and geocoding.
Whilst the example below will focus on their use in FME, the concepts discussed will apply to any tool or programming language that supports them, so even if you are not an FME user hopefully you will find the following discussion helpful.
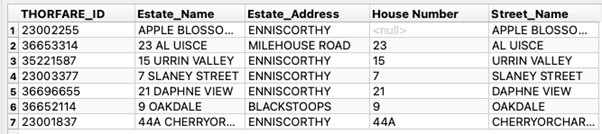
Recently we were met with a support call that required removing the numeric digits at the beginning of an address. The problem was that the number of digits varied. For example, the data had the following, 9 OAKDALE, 23 AL UISCE and to complicate it further, some entries were similar to 44A CHERRYORCHARD HEIGHTS where the 44A would have to be removed. The end result was to return only the text that fell after the space (OAKDALE, AL UISCE, CHERRYORCHARD HEIGHTS).
Our initial thoughts were that a regular expression would be involved in solving the problem. These are a somewhat hidden, and intimidating bit of functionality within FME that can be hugely powerful once you have gained a little mastery of them. Our initial attempt to use them didn’t give us the output we were hoping for. The digits were stripped from the beginning of the value, but a space remained and worse 44A CHERRYORCHARD HEIGHTS became A CHERRYORCHARD HEIGHTS.
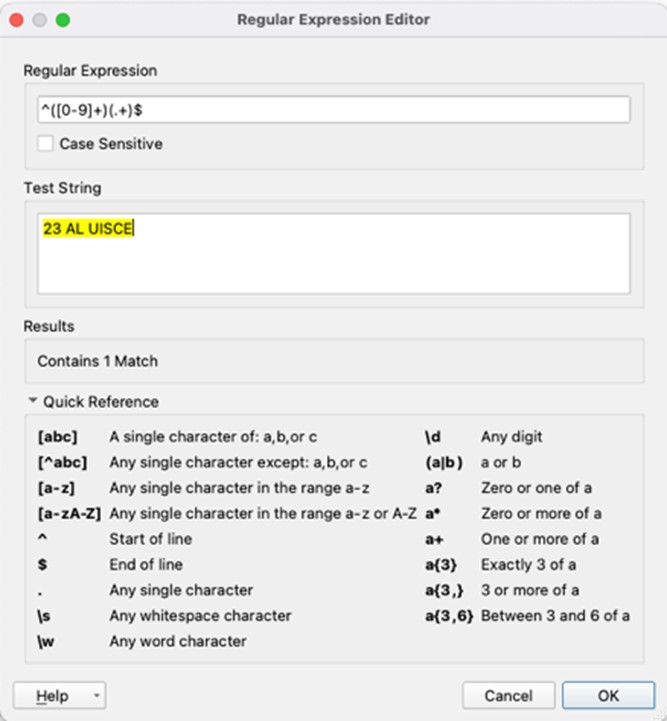
We went back to our workspace (Fig 1) and set about tweaking it to suit the issue at hand. The data was being fed into a StringSearcher transformer that had a Regular Expression parameter (Fig 2). We had found the initial expression from an online search and knew what this regular expression was doing from the output but we could not decipher what each symbol was doing or how to alter the expression to suit our needs. Our initial attempt was promising and looked like it was close to what we were after, so we decided it was time to get our head around the regular expression!
The first port of call was to look at the help for the StringSearcher parameter and try out the regular expression editor in the StringSearch transformer. Like the text editor which can be accessed in transformers that allow for text input this editor dialogue appears where you can insert a regular expression.
Our initial attempt let us see that we were matching the string and started to give us an idea of what the individual elements of the expression were doing but it was still quite confusing to see what the expression as a whole was doing. We then tried Michael Lovitt’s excellent online Rublar expression editor at https://rubular.com which let us see that our expression was actually matching two groups from the single match shown in FME’s editor.
Before we show you how we solved it we want to give a quick primer with regards to regular expression and hopefully take someone that has never used them before and make them (slightly) more comfortable with attempting to use them in the future. We’ll dive straight into the deep end with the expression from Fig 2 and the break it down.
Regular expressions are used for pattern matching. It is a sequence of characters (or symbols) that forms a search pattern and is generally applied to string matching. Let’s take a look at that expression in Fig 2:
^([0-9]+)(.+)$
This might as well have been hieroglyphics but when you break down the expression it actually quite simple. This expression states that the string must begin with at least one or more digits with each digit being from 0-9. So this can be 1, 26, 45, 111. The ^([0-9]+) is the part of the expression that tells us this. ^ means at the start or begin with. This is followed by a set of parentheses ( ). The parentheses indicate a capturing group. This is group 1. The next set of parentheses would be group 2 and so on. Don’t worry if capturing groups do not make sense at this stage, when we return to FME to talk through and run an expression it will be a lot clearer. Inside the first group we have [0-9]+, the [0-9] is a character set of 0, 1, 2, 3, 4, 5, 6, 7, 8 ,9 and the + means one or more. So if we take ^([0-9]+) you can see that this means, match strings that begin with one or more numerical digits. If the + was not present, this would mean that the string could only begin with one digit from the character set.
The next capturing group (.+) had us scratching our heads at first because it just contains symbols. The dot or period simply means match any character, like a wildcard. We have already met the + symbol. This group says match at least one character to any amount of characters. Again, if we removed the + it would only match one (any) character. The $ means the end of the string. So, match one or more characters until the end of the string.
Let’s look at that expression again in its entirety. The string must begin with at least one digit or more followed by at least one or more characters until the end of the string. We will use 9 OAKDALE as an example. This begins with a single digit so the initial criteria ^([0-9]+) is met. 9 belongs to group 1. This is followed by a space, which is also a character, and followed by seven more characters until the end of the string. This satisfies the (.+)$ and places OAKDALE(with the space in front of it) into group 2.
In the FME workflow in Fig 1, both groups will be output as the matched result recreating what we had initially! As we are using groups, we need to create a subexpression List under the transformers Advanced settings. This will output a List with two elements, one for each of our subgroups, this includes both the found string but also its starting position within the original string value.
So now we understand how FME is processing the current regular expression and can identify the sub groups how do we alter the expression to produce the desired output? We will need to look at a few more symbols and what they can do. To do this we are going to switch the focus away from the problem we are trying to solve and use another example relating to Irish mobile numbers. Take a deep breath and have look at the expression below:
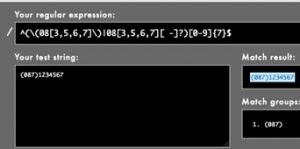
^(\(08[3,5,6,7]\)|08[3,5,6,7][ -]?)[0-9]{7}$
What is this madness? This expression is verifying how an Irish mobile number can be entered let’s say into a form. The number must begin with 08 followed by 3, 5, 6, or 7 wrapped in parentheses, OR begin with 08 followed by 3, 5, 6, or 7 followed by an option space or hyphen, and then followed by seven digits.
Before we go through the new symbols we are meeting here we want you to open https://rubular.com/ and copy and paste the expression into the top textbox. In the lower textbox enter (087)1234567, the entered text should highlight in yellow meaning that it meets the criteria set out in the expression (Fig 3). Next try 0871234567, then 087 1234567, and then 087-1234567 and note that these are all accepted by the expression.
Now try (087) 1234567, and then (087)-1234567. These will not highlight because they are invalid. Here is a list of other violations for you to test:
087-123-4567 hyphen separating after 123
087 123 4567 space separating after 123
084-1234567 4 is not a valid third digit
(081)1234567 1 is not a valid third digit
082 1234567 2 is not a valid third digit
0881234567 8 is not a valid third digit
Right, so we can see how a regular expression can detect a valid and invalid entry. Let’s go through this example and then use what we learn to fix the expression in our workspace. We know that ^ means at the start, this is followed by a set of parentheses. There is a large chunk within these parentheses. We will first look at everything to the left of the |
\(08[3,5,6,7]\)
The \ is an escape character meaning that whatever symbol immediately follows it should be considered a character literal to be searched for and not a part of the expression syntax. There are two in the snippet above that allows the expression to search for an opening and closing parenthesis. The opening parenthesis must be followed by a 0 and then an 8, so the beginning must match (08. The [3,5,6,7] is a character set. The next digit can only be one of these digits, so we are now at (083 or (085 or (086 or (087. These are then followed by the closing parenthesis. Therefore, our entry must begin with (08[3,5,6, or 7]).
But the | means OR, like a branch in computer programming. We will now look at the expression to the right of the | still within the original parentheses that are not escaped (capturing group). Our entry can begin with what was to the left of the | or the following:
08[3,5,6,7][ -]?
The above reads that our number must begin with 08 followed by 3, 5, 6, or 7, followed by an optional blank space or hyphen. The ? means zero or one occurrence, so after the initial three digits there can be one space OR one hyphen OR no space and no hyphen.
You should now be able to decipher what the first part of this expression is looking for:
^(\(08[3,5,6,7]\)|08[3,5,6,7][ -]?)
Entries that begin with the following:
(083) OR 083 (followed by a space) OR 083- OR 083 (no space, no hyphen)
(085) OR 085 (followed by a space) OR 085- OR 085 (no space, no hyphen)
(086) OR 086 (followed by a space) OR 086- OR 086 (no space, no hyphen)
(087) OR 087 (followed by a space) OR 087- OR 087 (no space, no hyphen)
The next part of the expression:
[0-9]{7}$
This reads seven occurrences of digits from the set of 0-9 and that is the end of the entry. An eight digit or entering a character that was not 0-9 would mean the entry is invalid. Therefore the curly braces { } is a quantifier of how many occurrences of the expression immediately before it should exist. If there was a {3} then only three digits could follow.
Let’s go through the full expression once more and make sure that we have a handle on this:
^(\(08[3,5,6,7]\)|08[3,5,6,7][ -]?)[0-9]{7}$
The entry must either begin with three digits wrapped in parentheses with the first two being 08 followed by either 3, 5, 6, or 7, OR begin with 08 followed by 3, 5, 6, or 7 with an optional space OR hyphen, followed by seven digits, each from 0 to 9. That reads so simple now that we know what we are doing.
We are now armed with what we need to rectify the expression to solve our issue. The problem we are faced with is that we have entries with one or more number of digits followed by a space, or one or more number of digits followed by a letter (44A) and then a space. We want to cut away those and only be left with the text that follows the space. Let’s begin to write our expression. We know that ^ means the start of or beginning of the string so we will start with that:
^
We have an OR situation where the value can have digits only or digits and a letter. We will begin to construct the first situation that will sit to the left of the |:
[0-9]+[ ]
Now to the right of the |:
[0-9]+[A-Z][ ]
We will wrap the left and right of the | in parentheses and put it together to give us the first part of our expression:
^([0-9]+[ ]|[0-9]+[A-Z][])
At this stage we have an expression that is matching values that begin with either one or more digits followed by a space OR one or more digits followed by a one character from the set A-Z followed by a space. This looks good so far and we can simply take the last part from the expression in Fig 2
(.+)$
and append it to our expression.
^([0-9]+[ ]|[0-9]+[A-Z][ ])(.+)$
Our full expression now matches values that begin with either one or more digits followed by a space OR one or more digits followed by a one character from the set A-Z followed by a space, followed by one or more amount of any characters until the end of the value.
We can now enter this into the Regular Expression parameter of the StringSearcher to see if it works. SUCCESS! The output now creates an initial subgroup containing the property number if present and the second group contains the estate name. We can add these as new attributes to our data as shown below in figure 7.
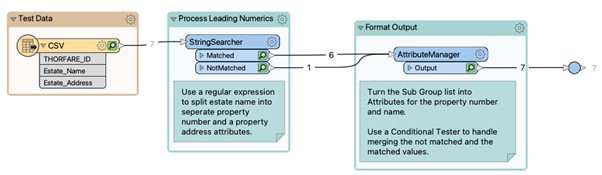
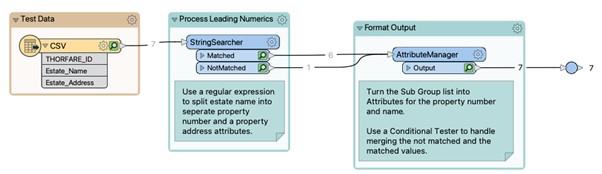
Before we finish up we want to talk you through the entire workspace presented in Fig 8 below. The Reader reads a CSV file consisting of three attributes. The Estate_Name is the one we are interested in and wherein our problem lies.
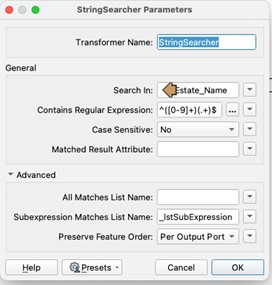
The Reader connects to a StringSearcher transformer where we set a few parameters (Fig 9) as shown below:
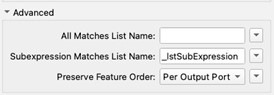
As mentioned earlier the Matched Result attribute will output the same value as Estate_Name because our regular expression matches all of the elements of the string, so it’s considered a match. As we are matching subgroups, we can leave this blank to stop FME creating an unneeded attribute and under the Advanced section we can enter a name for the output list that will contain the matched groups from our expression. Our first group from ([0-9]+[ ]|[0-9]+[A-Z][ ]) is going to be placed in _lstSubExpression{0}, therefore, the 1 , 22 , 101 , 44A , each followed by the space, will be placed in here. Our second group (.+) is what we are most interested in, this contains everything after the space and gets placed in _lstSubExpression{1}.
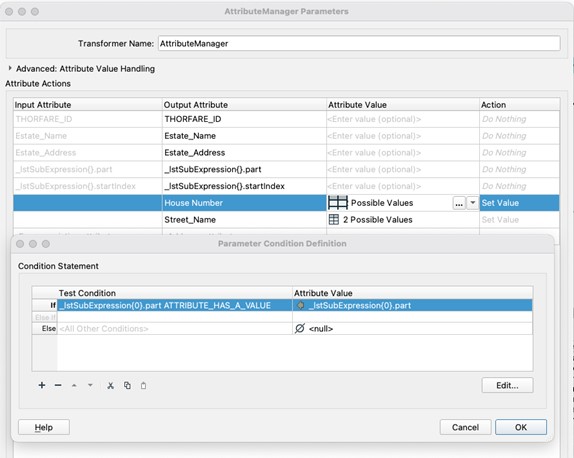
The results from both ports of the StringSearcher are passed into an AttributeManager which handles both the matched and unmatched results and creates two new attributes representing the House Number and the Street Name. This is done through the use of Conditional Tests as shown in the figure below.
The conditional tests, check to see if the first list element has a value and if it contains a property number adds this as the House Number, if it doesn’t which would be the case of the unmatched records, we explicitly declare the output as Null, so we know we do not have data for this field. A similar set of tests are carried out to populate the Street_Name attribute. Our list is well ordered as a result of the matching process, we know this will be the second item in the list we can use the list element order to determine which part of the list to use.
The AttributeManager demonstrates how it is possible to combine a number of steps by allowing us to wrap up the step of creating the attributes, merging those cases without a property number and cleaning up the data flow by removing the lists in a single step.
Hopefully this will have shown how powerful regular expressions can be and might be used to solve some of your future problems.
Just to test if you have learned anything from this post check out the expression below that does the same as our final expression but more compact and without an OR | branch. Does this make sense to you?
^([0-9]+[A-Z]?[ ])(.+)$
Hopefully our journey through regular expressions has shown how powerful they can be as a tool for pattern matching strings and can be used to validate data such as telephone numbers, Eircode’s, or to aid with address cleansing problems as we seen in this example.
Alongside the examples we’ve touched on you can find online cheatsheets such as can http://www.cheatography.com/davechild/cheat-sheets/regular-expressions/that can help turn the hieroglyphics into understanding.
We will leave you with one final note; although most implementations of regular expressions are extremely similar there can be slight differences, this means small differences in your data can mean the difference between a match or not so it’s always good to thoroughly test your expressions and transformers like the Sampler can create a subset of your data for this.
Finally, here is one last challenge can you see how this slightly modified version of the expression above differs and do you think it’s a better solution?
^([0-9]+[A-Z]*[ ]*)(.+)$
Bob Stuart, Managing Director IMGS:
Bob has over 30 years (18 years at IBM in Ireland) IT industry experience in Customer Service Engineering, Human Resources and Sales and General Management. Bob believes that the key to IMGS’ success is a focus on providing top class support and excellent customer service to our customers.
Ciaran Kirk, Operations Director IMGS:
With over 20 year’s experience and a proven track record in delivering enterprise solutions which deliver significant savings for customers through the intelligent use of Data I am passionate about achieving real digital transformation through data agility.
Aoibhinn Stuart, Delivery Director IMGS:
Aoibhinn has over 15 years project delivery experience across a wide variety of industries, including Banking, Payments, Insurance and Utilities.
She is passionate about customer service and the importance of building strong collaborative business relationships. She is ISEB, ITIL and Scrum.Org accredited with a strong understanding of complex IT systems and processes. Aoibhinn specialises in project management, process improvement and quality assurance to improve system stability, functionality and efficiency.
Garrett Cronin, Commercial Manager IMGS:
With over 15 year’s experience, I have a proven, multi-award winning track record in helping companies achieve their goals.
At IMGS, I support enterprises to drive digital transformation through data agility. As a company, data intelligence and information is at the core of what we do. We provide solutions to automate data flows, visualise information and power data insights for a wide variety of customers including Local Authorities, Government Agencies, Utilities and Communication Organisations.
IMGS is a Safe Software Gold Partner. Safe Software is a world leader in Spatial data Extraction, Transformation and Load (ETL) technology..
IMGS partners with Hexagon Geospatial to provide organisations with powerful solutions that help make sense of the dynamically changing and challenging world..
IMGS is the sole distributor for Hexagon's Safety & Infrastructure division for the island of Ireland.
Talend is the leading open source integration software provider to data-driven enterprises, allowing companies to connect to their information at big-data scales, higher speeds, and reduced costs.
IMGS are proud to work with Sisense, a leading platform for analytics builders that simplifies business analytics for complex data.
IMGS, a solutions partner in Ireland for Snowflake Computing, deliver a cost-effective low maintenance, modern data warehouse as a service through Snowflake.